今まで「Rubyのuniqは遅い」という思い込みをしていました。ある配列から重複を取り除いた配列を作り出すためにはいくつかの方法が考えられますが、何が効率的なのか、実測してみました。
試した方法は以下の4つです。
-
Array#uniq
-
Array#uniq!
-
Set
-
Hash
それぞれのコードは最後に掲載するとして、さっそく実測値です。使ったマシンはmacbook air 11’。CPUは1.6GHz Intel Core 2 Duo。メモリは4GBです。rubyのバージョンは以下になります。
yoichiro$ ruby -v ruby 1.9.2p180 (2011-02-18 revision 30909) [x86_64-darwin11.3.0]
それぞれ5回実行して、その平均を比べてみました。0〜99までの数値を100万個持つ配列を作り、それから重複を排除した配列を求めます。
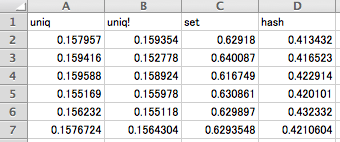
最後の行が平均値です。それをグラフで並べると、差ははっきり見て取れます。
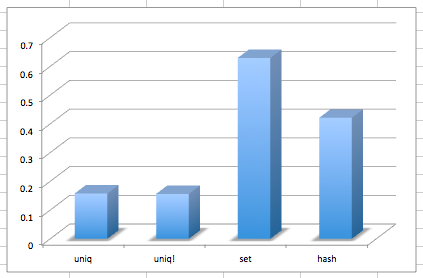
uniqが遅いなんて言ってごめんなさいごめんなさい。今では、ある配列から重複を取り除いた配列を得たい場合は、素直にuniqを使うべきですね。
追記: 2012/05/28 コメントにあるように、確かにhashに有利なデータセットでのみの試験となってしまってました。深く反省いたします。。。
実際に測ってくれた結果をグラフにしたのが以下となります。
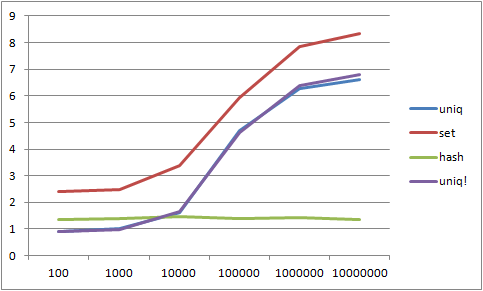
これからわかることは、要素数(上記の場合は100,000個)に占める重複の割合が1割を下回ってる場合はuniqメソッドの方が速く、1割を超えている場合はhashを使ったほうが速い、という結果でした。
追記ここまで
最後にそれぞれのコードを掲載します。もしフェアな比較になってないなどあれば、コメントください。
uniq
source = Array.new
1000000.times do |i|
source << rand(100)
end
# Start
s = Time.now
result = source.uniq
# End
e = Time.now
puts e - s
puts result.lengthuniq!
source = Array.new
1000000.times do |i|
source << rand(100)
end
# Start
s = Time.now
source.uniq!
# End
e = Time.now
puts e - s
puts source.lengthset
require 'set'
source = Array.new
1000000.times do |i|
source << rand(100)
end
# Start
s = Time.now
result = Set.new
source.each do |i|
result << i
end
# End
e = Time.now
puts e - s
puts result.lengthhash
source = Array.new
1000000.times do |i|
source << rand(100)
end
# Start
s = Time.now
hash = {}
source.each do |i|
hash[i] = 1
end
result = hash.keys
# End
e = Time.now
puts e - s
puts result.length