夜は寝れなかったものの、寝過ごすことはなくちゃんと起きることができたGoogle I/Oの2日目。昨日のKey noteはAndroid一色な内容だったけど、今日はきっとSocialについての何か新しい発表があるに違いない!と思ってワクワクしながら会場に向かいました。昨晩はペンネを少ししか食べず、空腹で目が覚めたといっても言い過ぎではありません。会場で出される朝食はベーグル以外「デザート」と言ってもいいくらいのラインナップ。甘いパンケーキを2枚食べ、2階へと向かいました。
今回のGoogle I/Oでは、日本から参加した人は40人前後だったと記憶しています。Key noteが始まる前に、そんな日本人がGTUGのブース前に集合しました。既に多くの人が3階に移動してしまった中、異国の会場に以下の写真のようにこれだけ日本人が集まっているのも変な感じです。震災や原発、さらにはたった59分で売り切れたチケットの問題などがありながら、これだけの人と会場で会えたことは、感慨深かったです。

昨日以上に気分は楽しくなっています。その気持ちを表に出そうと、滅多にしないようなこともやってみました。はぃ、旅の恥はかき捨て、ですよね?
さて、Google I/Oの2日目に参加したセッションの概要を、前のエントリと同様にまとめてみたいと思います。
Building Custom Client Libraries for Google APIs
Googledでは数多くのAPIが提供されていますが、これらのAPIを呼び出すコードを書くことは結構大変な作業です。そこでGoogleでは、API discovery serviceに基づいて、APIにアクセスするためのクライアントコードを出力するためのツールを提供しています。本セッションは、どのようにAPIがDiscovery serviceにて説明されているか、そしてクライアントコードを得るためにどうすれば良いかを開設する内容でした。

GoogleのAPI群は、RESTful APIであり、リソース、メソッド、そして各メソッドのためのパラメータから成り立っています。各APIは、Discovery文書により説明され、そしてメタデータはクライアントライブラリ内でAPIのストラクチャを決定するために使われます。Discovery serviceのベネフィットは、スケーラビリティ、自動化、そして透過性です。ちなみに、Google APIs Explorerを使って、Discovery文書に基づく各APIの説明と実際の呼び出し結果をWebブラウザ上で確認することが可能となっています。このAPIs Explorer自体もオープンソースであることが驚きですね。このツールを使うことで、Discovery文書にて各APIのためにどんな説明がされているかを知ることもできます。Discovery文書は、Google APIs Client Librariesだけでなく、Google Plugin for Eclipseでも使われています。
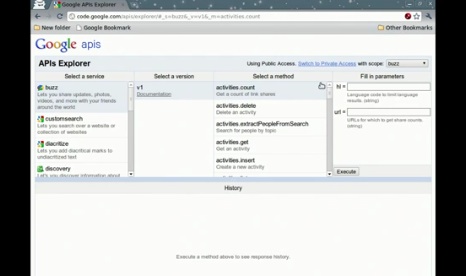
Discovery文書やその利用シーンなどの紹介のあとは、Discovery文書の実際の中身についての解説が始まりました。基本的には、Discovery文書は各APIがサポートするメソッド、パラメータ、リソースとそのスキーマ、そして認証についてを説明します。そして、全てのレスポンスはJSONベースです。JSONの構成は、itemsプロパティの中に持つ各オブジェクトとして、APIの特定のバージョンの仕様が記述されます。APIの情報としての最も基本的な情報としては、以下の内容が記述されます。
-
name
-
version
-
description
-
icons
-
documentationLink
何はともあれ、まずはDiscovery文書を入手するところから始めます。“https://www.googleapis.com/discovery/v1/apis/“というURLの末尾に、欲しいAPIの種類を記述してアクセスすると、そのAPIのDiscovery文書を得ることができます。この文書には、上記の内容の他にも、以下の重要な情報が含まれています。

-
authプロパティ: 認証に関する情報。
-
schemasプロパティ: リクエストやレスポンスの本文の構成を規定する情報。
-
resourcesプロパティ: URLやメソッド、パラメータの情報。
authプロパティ値として書かれる認証に関する情報は、いくつかのAPIで必要とされる認証のための情報を記載します。今では多くのAPIはOAuth 2.0が適用されていますので、OAuth 2.0に必要な、例えばscopeの情報などが記載されます。
schemasプロパティやresourcesプロパティでは、いくつかの標準仕様が組み合わされています。
-
URI Template v04: APIのURIを規定。
-
JSON Schema draft-03: 各パラメータの名前や型、リクエストやレスポンスの本文構造を規定。
Atomフォーマットを採用していた一昔前のWeb APIであれば、Discovery文書もRSDなどで説明され、XML Schemaと組み合わせて利用されていたと思います。今日ではAPIでやり取りされる情報の書式はJSONが当たり前になっていますので、GoogleのようにJSONにてAPIのDiscovery文書が記述されるのはむしろ自然と言えるでしょう。
次に、このDiscovery文書を使って作られたクライアントライブラリの話が紹介されました。クライアントライブラリの作成は、「Discovery文書をフェッチし、リソースやレスポンスをビルドし、それを使ってRESTコールと結果をフェッチさせる」という手順となります。

このセッションでは、Python版のクライアントライブラリのコードを取り上げながら実際の処理を説明していました。URL Shortener APIを例にしたクライアントライブラリの実際のコード例として紹介されましたが、そのPyhtonコードの長さは、たった35行です。
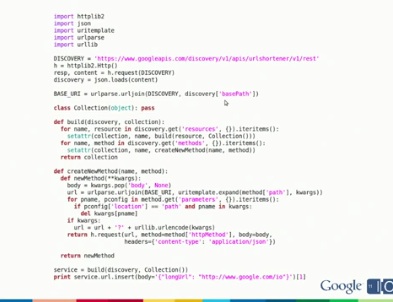
また、自作しなくとも、すでにPython、Java、PHP、Ruby、そして.Net向けにGoogleからクライアントライブラリが公開されています。まだStableなものはなく、BetaあるいはAlphaです。これらを使うことで、開発者は楽にGoogleの各種APIを利用することができるようになるでしょう。
APIの利用者は、APIにアクセスするためのコードを書きたいのではなく、APIを使ったアプリケーションを作りたいという気持ちを持っています。本質的なコーディングに集中するためにも、このDiscovery文書とクライアントライブラリの存在は大きいでしょう。Discovery文書が書ける、ということは、すなわちAPIの設計が統一化されている、ということになります。mixi Platformでも参考にして同じような環境まで持って行きたいな、と思ったセッションでした。
Identity and Data Access: OpenID and OAuth
このセッションは、事情があって最初から参加することはできませんでした。前半はOpenIDの話だったっぽいのですが、僕が入室したときにはOAuthの話になっていました。OAuthに対応しているAPIは、現在35あります。話の内容としては、各アプリケーションやサービスにパスワードを渡すことなく、Googleのサイトにて認証を行い、その結果サービスに情報を渡すことをユーザに同意させ、その後で初めてAPIを利用することができるようになる、という基本的なOAuthの考え方と処理フローが説明されていました。

このセッションでは、OAuth 2.0で最も一般的なWeb Server Profileについて、各パラメータの内容なども含めて、詳細に説明が行われました。また、まだOAuth 1.0aも現役ですので、OAuth 1.0aでのプロテクテッドリソースへのアクセス方法についても紹介されていました。エンタープライズ向けという性質の強いAPIは、まだOAuth 1.0aベースなようでした。
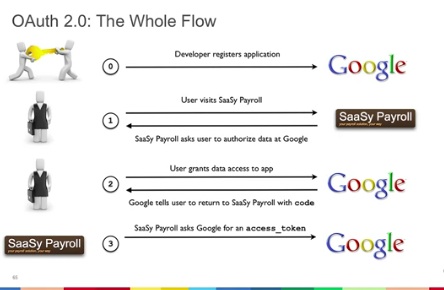
OAuthを知らない人は、このセッションを見ることで、OAuthによる認証認可手順の把握がしやすいでしょう。かなり細かく親切な説明が続きますが、これはRyan Boydの人柄と言えるでしょう。
Beyond JavaScript: Programming the Web with Native Client
今年のGoogle I/Oで最後に聞いたセッションがこれです。何でこれにしたかというと・・・他に気になるセッションがなかったから、という残念な理由になります。AndroidのMemory management for Android appsと迷ったんですが、最後はより技術に尖ったセッションを、と思って選択しました。結果としては、うーん、微妙かな。
このセッションでは、NaClの紹介と実際のデモを見ることができました。Webアプリケーションと言えば、HTML、JavaScript、Flashなどの技術が主に使われますが、NaClはCやC++のバイナリコードをWebブラウザ内で実行させるという、かなり思い切った技術となります。言い方としては「ネイティブコードを安全に実行するためのサンドボックス技術」となります。

そのコードはクライアントのCPUで実行され、インタプリタはなく、POSIXライクなプラットフォーム独立となります。そのため、非常に強力なセキュリティが備わっています。つまり、実行されるコードは、実行前にベリファイされます。たとえば、行儀の悪いことが試されたときは、コードは停止します。ファイルシステムへのタッチ、プロセスの生成や破棄などがそれにあたります。

なぜNaClを使うか、それはいくつか考えられます。一つは「言語の選択」。C++で書かれたコードがあったとき、それをJavaScriptで書き直したいと思いますか?次にパフォーマンスです。コードはCPUやGPUにダイレクトにアクセスすることができ、またSIMDやマルチコアCPUの恩恵を受けることができます。さらに、アプリケーションプラットフォームとしてブラウザを使うことができるようになります。そのアプリケーションの配信が簡単で、ユーザはインストールすることなく、そしてChrome Web Storeにて販売することが可能です。
このセッションのデモは、実際にPythonコマンドを使って、新規にプロジェクトを生成するところから始まりました。ChromeはデフォルトではNaClがOFFになっているので、それを有効にする必要があります。NaClのHTMLへの埋め込みは、embedタグで行われます。type属性にはapplication/x-naclと設定され、src属性にnmfファイルが指定されます。このファイルは、CPUのアーキテクチャごとに実行されるnexeファイルが記述されます。NaClランタイムは、このnmfファイルに基づいて、実行するコードを選択します。
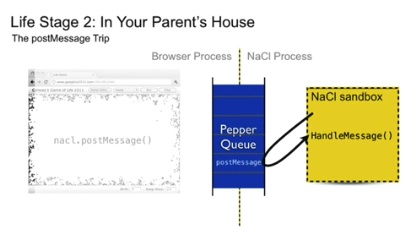
JavaScriptとC++との連携は、一種のメッセージング機構によって実現されます。たとえば、JavaScript上でpostMessage関数を利用することで、Pepper Queueにそのメッセージが入り、そしてそのメッセージはNaCl Sandbox内のメッセージハンドラによって消費されます。
もちろんデモの中では、マルチコアCPUの恩恵を受けた結果パフォーマンスが実際に向上したことも視覚的に示されました。さらに、オーディオファイルを再生するデモもありました。NaClコードの優位性がよくわかるデモでした。
HTML5が非常に注目され、各WebブラウザはHTML5に最適なチューニングを施すことに注力しています。しかし、本セッションのまとめとして、NaClにてHTML5をよりサポートすること、開発環境を整備すること、GCやJITを搭載すること、などが今後の目標として紹介されました。アプリケーションの分野によっては、NaClはとても良い選択肢になるでしょう。たとえば、暗号化などの多量な計算などは、その範疇と言えると思います。
2日目の参加セッション数が少ない理由
といっても1つ少ないだけですが、これには2つ理由があります。一つ目は、Google I/Oの会場で、とある企業と打ち合わせをしていたこと。もう一つ目は、「限定された人しか入室できない秘密のセッションに参加していた」ということです。どっちも詳しくは話すことができないのですが、特に2つ目は、なかなか貴重な体験をさせていただきました。もし来年もこれがあった場合は、勇気を出せるように1年間かけて準備したいな、と思っています。
この日の夜は・・・
API Expert仲間とは別に、サンフランシスコに来ていたミクシィ社員と一緒に夕食となりました。Google I/OではAPI Expertといつも一緒に行動している印象が強かったので、ちょっと意外な感じでしたが、いろいろと面白い話をすることができました。
明日はGoogleplexに行って朝食をいただかなければならないため、かなりの早起きです。昨夜と違って、今夜は食事もしっかり食べ、お酒も入っています。「今までも疲れもあるし、今夜は寝れそうだな」という期待は、見事に外れます。またもや深夜3時近くまで寝れない。。。
Google I/O 2日目での写真は、以下のURLから見ることができます。
http://www.facebook.com/media/set/?set=a.10150185083449539.327897.579499538&l=fc327fc37d
Google I/O 2011は、今年もあっという間に終わってしまいました。Key noteはAndroidとChromeのみ。Google AppEngineのGo言語対応という大きなニュースですら、一切Key noteでは触れられませんでした。Googleの今向いている方向がとてもはっきりと明確に示された、そんなGoogle I/Oだったと思います。2日間とも、僕が聞いたほとんどのセッションにGoogleのSocialチームも来ていたことが、よく説明できないけど、何かホッとした印象を持ちました。僕の興味の方向は、少なくともGoogleのSocialチームと一緒だってことですよね!?