今年の前半、ある限定した範囲で使うツールを以下の構成で作ってました。
-
Ruby 1.9.3
-
Rails 3.2
-
Dojo toolkit 1.7
Railsで何かを作るのが久々だったこと、 Erlangで最初作ったものをRubyベースでPortingすること、という背景があったのですが、実際に僕がRubyベースで書き直したときの書き方が結構満足いくものだったので、それをここで紹介してみたいと思います。もちろん、ドメインモデルへの考え方、RESTfulなWebアプリケーションの作り方、MVCモデルの適用、などなど「Railsならこうするだろ」というものがありますが、
「 広く一般に言われているセオリーは一切気にせず自分が作りやすい組み方をする」
という至極自己中心的な考えを持って確立されたのが以下に説明することになります。
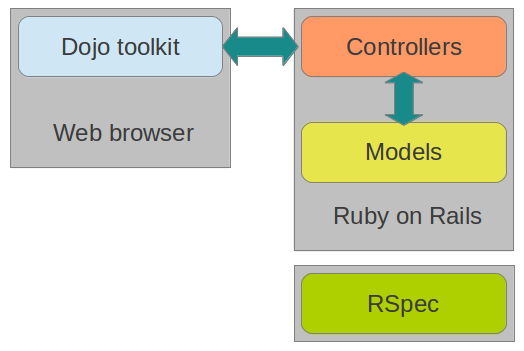
すっごく違和感を持つ人も多いと思いますが、「こんな作り方もできるんだ〜へぇ〜」程度に捉えてもらえるといいかなと。
ポイント
とにかく重視したのは、「 テストのしやすさ書きやすさ」です。ホント、これに尽きます。ちょっとでもテストがしにくくなった瞬間に完敗、くらいの意気込みです。どうせ後でテスト書くなんてできないんだから、最初からテストを最も書きやすい環境にしてそれを維持していくことが重要です。テスト原理主義です。そのためなら、多少の犠牲はやむなしです。世間からどんな批判を浴びようとも品質第一であるべき、そういうことです。
これ、Rubyなどコンパイラがなく動的な型付け言語であれば、全てに当てはまることだと思ってます。ソフトウェアは一人で維持していくことなど不可能です。誰かに手伝ってほしいと言われたとき、そのソフトウェアの品質がどう保たれているかはとても気になります。「一切テストがありません」「○○な部分はテストコードないんですよねー」って言われた瞬間に、全力で逃げたくなりますよね。そういう状況を作らないようにしようとすると、そしてそれを完全に貫くようにしようとすると、個人的な印象では「世間で言われている綺麗な書き方」がどうしても当てはまらない局面はあると思ってます。
なので、以下に書くことのほとんどの事項には「テストがしやすくなるから」という理由ばかりが出てくるはず、です。
ポイントを抜き出した全体感は以下となります。
モデル ・作成単位はテーブルごと ・処理は「クラスメソッド」として書いていく ・最初にLookupするリソースに所属させる ・必要であれば「ActiveRecordを継承しない」モデルクラスを作る ・モデルはカバレッジ100%を目指す
コントローラ ・コントローラ内でモデルをnewせず準備されたクラスメソッドのみを使う ・作成単位は「1リクエスト1コントローラ1アクション」 ・HTMLを返すのは”top/index”のみ ・AJAXリクエストは”ajax/[Verb + Target]“とし、全てPOSTメソッドに統一する ・AJAXリクエストは全てJSON文字列をレンダリングする
JavaScript ・assets/javascriptsに置かずpublic/jsに置く ・AMD準拠の遅延ロードの仕組みを使う ・BootLoaderクラスを作る ・Publish/Subscribeモデルをうまく使う ・標準の関数構成を使う
では、それぞれ紹介していきましょう。
モデル
紹介の順番として、DBに近いところから順にフロントへという感じで見ていきましょう。まずはモデルクラスからです。
モデルクラスは「やりたいことが全て書かれている場所」とします。そして、「モデルクラスが提供してくれる○○メソッドさえ呼べば、全ていろいろやってくれて結果がまるっと得られる」という風になってる状態を目指します。シンクロナイズドスイミングの「リフト」は、水面から宙に舞う人は一人ですが、実際には水中で多くの選手が頑張っていろいろやってるからこそ、水面の人は宙返りを簡単に行えます。モデルクラスは、その水中の人たちなイメージです。
そして、モデルクラスはテストコードがふんだんに書かれる部分になるべきです。作っているアプリケーションで起きうる様々な状況を全て網羅することを、モデルクラスのレイヤで保証します。モデルでできていないことは、他のどのレイヤでもできていないことになり、すなわちアプリケーションでできないことです。
この状態にするために、いくつかのポリシーがありますので、細かく見ていきましょう。
作成単位はテーブルごと
Railsにおけるモデルは、O/R Mapperの機能を持っています。そのため、基本的にモデルクラスの作成単位は、リレーショナルデータベースの表の単位と一致します。
これは崩さずそのまま適用します。つまり、「1テーブル1モデルクラス」です。実際これを崩すと、ActiveRecordが提供してくれる機能がほとんど機能せず、何のためにRailsを使っているのかわからなくなってしまいます。
もちろん、このポリシーは「適切にデータベースの設計ができていること」が前提となります。具体的には、エンティティの抽出がうまくいっていれば、モデルクラスを作って実装していく際に困ることは少なくなります。
処理は「クラスメソッド」として書いていく
データベースや外部との通信を行いながら、アプリケーションに必要な所謂「ビジネスロジック」をモデルクラスに追加していきます。モデルをO/R Mapperとして割り切ることはせず、ビジネスロジックも各モデルに持たせていきます。
ここでポイントなのは、「クラスメソッドとして作っていくこと」です。普通にメソッドを足していってはいけません。クラスメソッドとして、が重要です。
つまり、コントローラからモデルが持つ機能を使いたい場合に、
user = User.new(...)
user.foo(...)とするのではなく、
User.foo(...)で「全て」が済むようにしておきます。基本的に、モデルレイヤ外からは、インスタンスメソッドは「個別の値を取り出す」といったこと以外は叩かない、っていうポリシーです。newを別レイヤからすることなんぞ、もってのほかです。何か新しいリソースを作成したい場合は、それ専用のクラスメソッドを作ります。
class User < ActiveRecord::Base
...
def self.create(...)
new_user = self.new(...)
# Do something
new_user
end
endデータベースから消したい時、内容を更新したい時も同様に、それ専用のクラスメソッドを準備します。オブジェクト指向であれば、「いやいや、操作したい対象のインスタンスに対して処理するのが常識だろ」になると思うのですが、モデルレイヤ外にそれを強いることはしません。操作対象のIDをもらって、そのIDに対応するインスタンスを見つけて、それについて何かする、というクラスメソッドを作ります。
class User < ActiveRecord::Base
...
def self.change_password(id, old_it, new_it)
target_user = self.find(id)
# 本当は生パスワードを扱ってはいけません!
current_it = target_user.password
if current_it == old_it
target_user.password = new_it
target_user.save!
else
# Raise exception
end
end
end基本的に、各クラスメソッドの引数は、具体的なインスタンスではなく、IDを使います。そのIDに対応するルックアップは、クラスメソッド内で行うことです。
なぜこのようにするのか、理由は以下です。
-
Webアプリケーションにおいて、Webブラウザとやり取りされる情報は「インスタンスではなくID文字列」である。そのため、各コントローラがまず知るものはID文字列であり、それを何も考えることなくモデルに渡すことだけにコントローラを専念させたい。
-
結果として、モデルの各クラスメソッドが「他のレイヤから見た時にFacadeとして機能」するようになる。
各クラスメソッドの処理結果については、モデルクラスのインスタンスまたはその配列だったりします。それはあくまで「やりたいことを全てやったあとの結果」であり、コントローラはその結果から情報を取得するだけとなります。
モデルクラスには、他のモデルとの関連や、バリデーションルール、取得の際の制約(論理削除されたものは対象としない、など)が記述される可能性があります。例えば、以下のようなコードです。
class User < ActiveRecord::Base
validates_presence_of :first_name
validates_presence_of :last_name
...
belongs_to: Group
...
endこれは僕の主観であってRubyの「ダックタイピング」の思想からは外れると思ってるのですが、明確に自分で書いたメソッドがあって、それに対してその振る舞いを確認するテストコードを書きたい、っていう気持ちがあります。通常、期待通りに上記のような制約が有効になっているかどうかを確認するために、Userクラスをnewしてcreateしてみて・・・という処理をテストコードの中で書くことになるかと思います。が、「必ずクラスメソッドでインスタンス生成用の機能を提供すること」とポリシーを決めてあげれば、そのメソッドの振る舞いの延長線上に制約の有無がチェックできる、つまりクラスメソッドの引数の渡し方のバリデーション次第で同時に制約のチェックができる、っていう状態に持っていくことを好んでいます。
と、書きながら自分でも理由としては弱いな、と思ってしまっていますが、まぁメインの理由はモデルへの操作を外部に一切任せないっていうことです。このポリシーによって、モデルに関する操作は全てモデルクラスへのテストコードとして記述することになります。そして、モデルレイヤと他のレイヤとの分離をはっきりとさせることができます。
最初にLookupするリソースに所属させる
モデルクラスにクラスメソッドを追加していることの理由として「結果としてFacade的に機能するようになる」と書きました。ただし、作っていく中で「この処理はどのモデルクラスに持たせるのがいいのだろうか?」という疑問が沸くと思います。ドメインモデルをちゃんと作る際によく当たる壁ですね。確か「最も近しいエンティティに持たせる」という、曖昧にも思える指針がよく言われていると認識しています。
この問題は、まさにそのようにします。個人的にはこれは「決めの問題」だと思っているのですが、自分の中でこれもポリシーができています。
先ほど、「全てのビジネスロジックはクラスメソッドとして作成し、引数にIDをもらう」と説明しました。つまり、IDをもらうということは、そのビジネスロジックで行われる最初の処理は「あるリソースのLookup」になることがほとんどです。この「最初にルックアップされるであろうリソース」、まさにそれに対応するモデルクラスに持たせれば良い、という歩シリーです。
悩んだところで自分が納得のいく理由を強引に編み出して決めていくわけですし、何らか統一されたルールに基づいていればいいと思っています。このポリシー、自分でやってみて意外と機能します。あとでできあがりを見渡してみても、かなり整理された形でバランスよく各モデルクラスに配置されるようになります。
必要であれば「ActiveRecordを継承しない」モデルクラスを作る
ビジネスロジックは、極力モデルクラス、特にデータベースの表と対応しているモデルクラスのどれかに持たせるべきです。ただし、かなりの規模のアプリケーションで、データベースの表が非常に細かく数も多かったりすると、かえって「どこに何を書いたのかわからない」ということになりかねません。
もしデータベースの表を重視するのではなく、業務の分類を重視したいのであれば、それ専用のモデルを作ってしまうのも手です。先ほどはクラスメソッドがFacadeの役目を示すと言いましたが、明確にFacadeとして機能するクラスを作ってしまう、というわけです。
ただ、これも「モデル」としてapp/models下に配置すれば良いと考えています。そして、ActiveRecord::Baseも継承しない、ただのクラスとして作ります。
よく「O/R Mapperとして機能するものがapp/models下に配置されるのであって、そうじゃないものはレイヤが違うんだから別の場所(lib下とか)に入れるべき」という人がいます。それはそれで間違いじゃないし、選択肢の一つとして採用することもいいと思います。
ただ、僕の中では、
-
複数のモデルを扱いながら業務処理を行ってくれる「クラスメソッド」
-
複数のモデルを扱いながら業務処理を行ってくれる「クラス」
の2つがあった時、前者をモデルに持たせているのであれば、後者もそれはモデルでしょ?と思ってしまうわけです。モデル=O/R Mapper、にこだわる必要はないです。
どうしても分けたければ、モジュールを使って名前空間を分けるとか、そういうことをすればいいかと思います。何にしても、app/models下に配置すればいいかと。
モデルはカバレッジ100%を目指す
そんな風にしてアプリケーションの処理をモデルクラスに集中させてあげることで、当然テストの重点度はモデルレイヤが最も高くなります。ずば抜けた、と言っても言い過ぎではないでしょう。
モデルに関するテストは、Railsであれば最も手厚くサポートしてくれる場所であると思っています。Fixturesを使ってもいいし、Factory Girlとか使ってもいいし、とにかく充実しています。僕は日頃RSpecを使っていますが、手厚いサポートがあって、しかもActiveRecordが単純なDB操作を隠蔽してくれて、さらに上記のポリシーに従ってほとんどの大事な処理がモデルに集まっている、この状況が作れれば「テスト網羅率100%」を目指してもいいと思っています。
「は、無駄なもんまでテストコード書いてカバレッジ100%にこだわるなんて、どうかしてるぜ」
と思うかもしれません。でも、でもですよ。Javaじゃないんです。相手はRuby on Railsです。コンパイラはありません。そして、テストするまでもないものは、Railsにより隠蔽されていてそもそもコード中に存在しません。目の前にあるのは、どの記述もアプリケーションの動作に超影響を与えるコードの固まりだらけなはずです。「テストしなくてもいい場所」を探す方が難しいコードセットにモデルレイヤはなってるはずなんです。
そして、RSpecを使っていれば、なおさらです。コントローラに分散することなく、つまりトランザクション単位でまとめられた意味のあるクラスメソッド群に対していろいろな前提条件のテストコードをRSpecで書いていけば、それはもう「仕様書」です。ドキュメントに抜けがあったら、それは良くないですよね。
コントローラ
コントローラが向きあうことになるのは、DB寄りのモデルの他に、Webブラウザ寄りのHTMLやAjaxリクエストなどがあります。ここからはコントローラについてポイントを見ていきます。
コントローラ内でモデルをnewせず準備されたクラスメソッドのみを使う
モデルにがっつり処理を書いているおかげで、コントローラはかなりすっきりとした記述内容になります。
-
パラメータを取り出して
-
モデルのしかるべきメソッドに渡して
-
結果を元にJSONとなるべきオブジェクトを組み立ててrender
これだけです。モデルをゴニョゴニョすることは一切考える必要はありません。つまり、各アクションは以下のようなコードになるはずです。
class AuthenticateUserController < ApplicationController
def index
# (1) パラメータを取り出して
user_id = params[:user_id]
password = paramd[:password]
# (2) モデルのしかるべきメソッドに渡して
begin
user = User.authenticate(user_id, password)
# (3) 結果を元にJSONとなるべきオブジェクトを組み立ててrender
render json: {result: {id: user.id},
{name: user.name}}
rescue User::AuthenticationError
# Do something
end
end
...
end特に(1)と(3)についてコントローラではがっつり処理するとして、(2)を如何に頑張らずに済ませるか、がポイントです。どうしてかというと、(2)が軽量になればなるほど「モックを差込みやすい」というテストの書きやすさにつながるからです。
describe '正しいユーザIDとパスワードを渡して認証した場合'
before do
@user_id = 'user_id_1'
@password = 'password_1'
@name = 'name_1'
# ここから
user_mock = mock('User')
user_mock.should_receive(:id).and_return(@user_id)
user_mock.should_receive(:name).and_return(@name)
User.should_receive(:authenticate)
.with(@user_id, @password)
.and_return(user_mock)
# ここまで
params = {
user_id: @user_id,
password: @password
}
post :index, params
end
it 'リクエストが成功すること' do
response.should be_success
end
it '認証したユーザの情報がJSON形式で返却されること' do
response.headers["Content-Type"].should == 'application/json; charset=utf-8'
expect = {result: {id: @user_id},
{name: @name}}
response.body.should == expect.to_json
end
end「ここから」「ここまで」で囲まれた部分がポイントです。モデルとの境界面がひとつのメソッドのみとなっているため、とてもシンプルになります。「認証するだけの処理だからそうなってるんじゃないの?」と思うかもしれませんが、アプリケーション内で行われる処理のほとんどをこのようにシンプルな形にして、コントローラ内の責務を(1)と(3)に集中させることを目指します。
作成単位は「1リクエスト1コントローラ1アクション」
Railsの元々の思想は、あるリソースに対して行われる操作は、そのリソースに対応するコントローラが担当する、ということだと思います。1つのコントローラが複数のアクションを持てるようになっているのは、つまりそういうデザインができるということを意味しています。
ただし、ここではその思想を捨てます。リクエストの種類ごとにコントローラを準備し、各コントローラが持つアクションの個数は1つとします。
先ほどのAuthenticateUserControllerがそれを示す良い例です。普通であれば、UserControllerコントローラを作って、その中にauthenticateアクションを設けることでしょう。コントローラのクラス名は「リソースの名前+Controller」となるでしょうし、各アクション名はやりたいことを示す動詞が付く、となるかと思います。しかし、1リクエスト1コントローラ1アクションとなると、
-
コントローラ名: 動詞+リソース名+Controller
-
アクション名: “index”固定
というようになります。
なぜこのようにするのか、理由は「テストコードの均一な分割」です。
コントローラの作成単位は、そのままテストコードの作成単位そのものになります。リソースごとにコントローラを作っていくと、そのリソースに対して行う操作の量に応じて、コントローラが持つアクションの数が変わってきます。そのため、テストコードも同様にばらつきが出てくるため、もしかしたら「スッカスカなテストコード」と「超特大のテストコード」という感じになってしまうことがでてきます。
「超特大のテストコードを分割すればいいじゃん」と思うかもしれません。しかし、それによって新しい分割基準を編み出さなければならず、それはきっとコントローラごとに考えていく必要があり、非常に面倒です。人に説明するのも大変です。また、実装とテストコードの数が一致しないといった状況にもなり、見通しも悪くなってきます。秩序がだんだんとなくなってくるわけです。
さらに、ここで対象としているアプリケーションは、Ajaxを使った、リクエストが比較的細かなアプリケーションです。複数の機能を組み合わせて一つの画面を構成する、ということはWebブラウザ上で行われることであり、コントローラが行うことではありません。この場合、Webブラウザから依頼される処理単位に機能が分割されているほうが都合が良く、それにあわせていくと「1リクエスト1コントローラ1アクション」を前提に分割されることになります。
知りたいことの範囲外の記述ができるだけ目に入らない方がいいですよね?Ajaxを中心として組み立てられたアプリケーションでは、その特性を生かしたモジュール分割が大事になると考えた結果、自分の中では上記のポリシーが気持ちいいということになりました。
HTMLを返すのは”top/index”のみ
これはシンプルです。サーバ側で一切のHTMLレンダリングをせず、Dojo toolkitに任せるようにするので、その土台となるHTMLをtop/indexで返すのみです。
そのHTMLでは、例えばレイアウト構成をdijit/layout/BorderContainerで行うといった「あまり動的に変化しないもの」をdata-dojo-typeで直接指定してしまったり、あるいはダイアログ内のフォームなどの構成をHTMLで記述していったりします。JavaScriptで何でもかんでも動的に構築していくのも手ですが、その分JavaScript側のコードが読みづらくなってしまいます。
AJAXリクエストは”ajax/[Verb + Target]“とし、全てPOSTメソッドに統一する
config/route.rbファイルには、リクエストのパスと、それを受け取るコントローラ/アクションの組が列挙されます。Ajaxのリクエストを目立たせるために、パスの命名規則として「ajax/」を接頭語としてつけることにし、具体的な処理を「動詞+リソース名」にします。
これは、先程説明したコントローラ名の命名規則と一致させます。リクエストのパスから対応するコントローラのソースコードを素早く発見するための工夫です。
AJAXリクエストは全てJSON文字列をレンダリングする
これは説明の必要はないですね。JavaScriptで最も扱いやすい形式を採用すべきです。
JavaScript
Dojo toolkitを基本的に素直に使っていくことが、ここでのJavaScriptを記述する上でのポイントになります。Railsだから、という点は少なく、何となく自分で「これやっておいて良かった」と思えることを書いていこうと思います。
assets/javascriptsに置かずpublic/jsに置く
Dojo toolkitは1.6からAMDによる遅延ロードの仕組みを備えています。つまり、HTMLのheadタグ内でがっつりscriptタグを書くことはせず、必要になったら取りに行く、というスタイルとなります。
そのため、Railsが提供してくれるJavaScript関連の機能はあまり役に立ちません。普通にJavaScriptをロードできることの方が重要です。つまり、assets/javascripts下に置いてRailsの恩恵を受けるのではなく、public/js下に置いて普通に参照できるようにしておく方が自然です。
public/js下には、Dojo toolkit一式、および自分で書いたコードを配置します。例えば以下のようになるでしょう。
-
public/js/dojo-release-1.8.1 : Dojo toolkit
-
public/js/myapp : アプリケーションコード
AMD準拠の遅延ロードの仕組みを使う
Dojo tookitのバージョン1.6から、AMD(Asynchronous Module Definition)の機構が実験的に入りました。1.7では、AMDが標準となり、1.8ではそれが当たり前となっています。Dojo toolkit自体がAMDで書き直されているので、自分が書くコードもそれに習ってAMDを採用すべきです。
AMDを採用したクラス定義は、以下のようになります。
define([
"dojo/_base/declare",
...
], function(declare, ...) {
return declare("myapp.MyClass", null, {
constructor: function() {
// Do something...
},
...
});
});define()関数の第1引数には、依存する(つまり利用したい)モジュールの配列を指定します。Dojo toolkitでのクラス作成には”dojo/_base/declare”を使いますので、上記ではそれを依存モジュールとして指定しています。第2引数には、defineしたいものを返す関数を指定します。その関数の引数として、依存モジュールを受け取るための仮引数を列挙しておきます。まるでDIコンテナに依存性を注入されている感じです。
declare()関数には、クラス名、親クラス、そして定義したいクラスが持つ関数などが書かれたハッシュを指定します。constructor()関数は特殊で、名前の通りコンストラクタです。
上記で定義されているクラス名はMyClassなので、上記のファイルの配置は、
- public/js/myapp/MyClass.js
となります。
このMyClassクラスを実際に利用したい場合、以下のような記述を別のモジュールにて行うことになります。
define([
"dojo/_base/declare",
...,
"myapp/MyClass"
], function(declare, ..., MyClass) {
return declare("myapp.Client", null, {
constructor: function() {
...
var myclazz = new MyClass();
// Do something.
},
...
});
});define()関数に”myapp/MyClass”を依存モジュールとして指定します。それをMyClass仮引数で受け取った後、コンストラクタ内でnewしてインスタンスを生成しています。これがDojo toolkitを使ったクラス定義とその利用方法になります。
BootLoaderクラスを作る
僕はアプリケーションにおいて明確にエントリポイントを作って、それがアプリケーション全体を指揮するような作りにするのが好きです。全てが平等でそれぞれが調和して動作する作り方、というのもあると思いますが、残念ながらそのような素晴らしい設計できれいにうまくいったことは少ないです。
ここでは、BootLoaderクラスを作って、そのクラスに明確なアプリケーションのエントリポイント(起動時に最初に実行される入り口)を設けます。とにもかくにも、そこからコードを読んでいけば済むようにしておきます。
BootLoaderクラスとはいえ、先ほどのMyClassと定義方法は同じです。BootLoaderクラスをエントリポイントとするために、DOM生成完了後にまずBootLoaderクラスを読み込んでnewします。これにより、BootLoaderクラスのコンストラクタが、アプリケーションのJavaScriptにおけるエントリポイントとして機能するようになります。
<html>
<head>
...
<script type="text/javascript">
dojoConfig = {
async: true,
cacheBust: true,
packages: [{
name: "myapp",
location: "../../myapp"
}]
};
</script>
<script type="text/javascript" src="js/dojo-release-1.8.1/dojo/dojo.js"
data-dojo-config="parseOnLoad: true"></script>
<script type="text/javascript">
require(["myapp/BootLoader",
...
"dojo/domReady!"], function(BootLoader, ...) {
new BootLoader();
});
</script>
</head>
...
</html>dojoConfigのpackagesを使って自作JavaScriptモジュールを読み込めるようにして、その後Dojo tookitをロードします。そして、require()関数によりBootLoaderなどの依存ライブラリをロードし、BootLoaderクラスのインスタンスを生成しています。
ここでポイントは、“dojo/domReady!”を依存ライブラリに指定していることです。これはPluginと呼ばれていて、依存ライブラリとして読み込むことで暗黙的に特定の機能が発動するというものです。domReady!を指定することで、require()関数に指定した関数が、DOMの準備完了後に呼び出されるようにしてくれます。
BootLoaderクラスは、だいたい以下のような記述になります。
define([
"dojo/_base/declare",
"myapp/LeftPane",
"myapp/CenterPane",
...
], function(declare, LeftPane, CenterPane, ...) {
return declare("myapp.BootLoader", null, {
constructor: function() {
this.leftPane = new LeftPane();
this.centerPane = new CenterPane();
...
},
...
});
});コンストラクタ内で、LeftPaneクラスやCenterPaneクラスのインスタンスを生成しています。きっとそれぞれ画面の左や中央にある区画のUIを担当するクラスなのでしょう。そしてイベントハンドラの登録などもそれぞれ行われ、ユーザからの操作の受付準備が整うことになります。
Publish/Subscribeモデルをうまく使う
今までの例で、BootLoader、LeftPane、そしてCenterPaneという3つのクラスが登場しました。BootLoaderクラスは、アプリケーション全体の処理の調停役として機能させます。例えば、画面の左にあるメニューのどれかをクリックしたら、画面の中央の表示内容を変化させたい、というケースを考えてみましょう。
シンプルに考えると、LeftPaneクラスからCenterPaneクラスの処理を呼べればいいわけで、
this.centerPane = new CenterPane();
this.leftPane = new LeftPane(this.centerPane);というようにCenterPaneインスタンスをLeftPaneクラスのコンストラクタに渡してあげることで、直接的に操作ができるようになります。ただし、インスタンス間の関連がこれだと複雑になりがちなのと、画面の左以外の他の場所から同じ処理を呼ぶこともありえるため、できれば祖結合な状態を保っておきたくなります。
そのために、Publish/Subscribeモデルが使えます。Dojo toolkitでは”dojo/topic”という名前で機能が提供されています。
LeftPaneクラスからCenterPaneクラスへのメニュークリックによる画面切り替えを考えると、まず調停役のBootLoaderクラスにて、トピックを作って監視を始めます。
define([
"dojo/_base/declare",
"dojo/topic"
...
], function(declare, topic, ...) {
return declare("myapp.BootLoader", null, {
constructor: function() {
this.centerPane = new CenterPane();
this.leftPane = new LeftPane();
...
this.assignEventHandlers();
},
assignEventHandlers: function() {
topic.subscribe("changeCenterScreen",
dojo.hitch(this, "onChangeCenterScreen"));
},
onChangeCenterScreen: function(screenName) {
this.centerPane.changeScreen(screenName);
},
...
});
});topic.subscribe()関数がトピックを作って監視を始めるための関数です。トピック名と、それが発火したときに呼び出す関数を引数に与えています。上記ではonChangeCenterScreen()関数が呼ばれます。その中では、this.centerPane変数に対してchangeScreen()関数の呼び出し、つまり中央画面の切り替え処理を行っています。トピックに対して発火された際に、同時に渡されてくる画面名(screenName)もポイントです。
では、LeftPaneクラス内で上記のトピックに対して発火させたいときの処理を見てみましょう。
define([
"dojo/_base/declare",
"dojo/topic",
...
], function(declare, topic, ...) {
return declare("myapp.LeftPane", null, {
...
onClickShowHistoryScreenMenu: function(evt) {
topic.publish("changeCenterScreen", "history");
}
});
});topic.publish()関数を呼び出すだけです。第1引数はトピック名を、第2引数以降はトピック発火を受け取る側に渡したい情報を指定します。上記であれば、“history”という文字列がscreenNameになります。
もしかしたら「CenterPaneクラスでsubscribeするようにした方がいいのでは?」と思った方もいるかもしれません。それでもOKですが、個人的好みとしては、ただでさえPub/Subモデルは「どこで何が飛び交ってるかわからなくなる」ので、BootLoaderクラスを見るだけで把握できる、というようにしておく方が、後々の保守性は高いと考えています。
標準の関数構成を使う
最後に、これはより完全に好みの領域になると思いますが、複数のクラスに対して、できるだけ関数名を揃えておこう、というポリシーです。基本的にクラスの作成単位は、「ある画面の区画単位」であることが多いです。パネル単位、ダイアログ単位、フォーム単位、といったところでしょうか。これらはどれも、以下のような処理を行うでしょう。
-
画面を構成するDOM要素を組み立てて、UIを作る。
-
各UIにイベントハンドラを割り当てる。
-
画面表示時に、初期値を各UIに割り当てる。
これらを決まった関数名で記述しておくことで、どんなクラスを見たときにも同じように把握していくことができるようになります。例えば、以下のような感じです。
define([
"dojo/_base/declare",
...
], function(declare, ...) {
return declare("myapp.MyPane", null, {
constructor: function() {
...
this.createUIs();
this.assignEventHandlers();
},
createUIs: function() {
// Dijit、Dojoxの各Widgetの生成&配置など
},
assignEventHandlers: function() {
// createUIs()で作った各Widgetにイベントハンドラを割り当てる
this.***Button.on("click", dojo.hitch(this, "onClick***Button"));
...
},
onClick***Button: function(evt) {
// "***Button"がクリックされたときの処理
},
show: function(...) {
// この画面を表示する際に必要な処理
this.setInitialUIValues(...);
...
},
setInitialUIValues: function(...) {
// 各UIに値をセット
},
...
});
});上記では、イベントハンドラの関数名に対する命名規則「on+イベント種別名+UI部品名」も入れてみました。
先ほどの「LeftPaneクラスからCenterPaneクラスへのメニュークリックによる画面切り替え」の例であれば、show()関数をBootLoaderクラスから呼び出す際に、その引数としてscreenNameを与え、show()関数内で画面切り替えの処理を行うなどすればいいかと思います。
まとめ
以上、僕がRubyとRailsとDojo toolkitでAjax Webアプリケーションを作る際に適用した各ポリシーやデザインパターンを紹介してみました。巷で言われている作り方を無視していることもあると思いますが、その代わりに自分が開発をしていて「これは楽だ」と思ったことがあってのことだったりするので、その理由と共に読んでいただけたのであれば嬉しいです。良い面、悪い面あると思いますので、もし「こうしたほうがもっといい」ということがあれば、ぜひご指摘ください。